
참고 : https://www.redblobgames.com/pathfinding/a-star/introduction.html
순서
I. Path Planning 개요
II. Breadth First Search (BFS)
III. Dijkstra
IV. Heuristic (Greedy BFS)
V. A* (A star)
I. Path Planning 개요
Path Planning은 말 그대로
Start 지점에서 End 지점까지의 경로를 찾는 것이다.
하지만 내가 Start 와 End 를 모두 안다는 가정은 없다.
End를 모를 때, 알고 있을 때 그에 맞는 알고리즘이 존재한다.
이 글은 End 정확히 알고있는 "Global Path Planning"에 관한 방법이다.
스타크래프트, 롤 등 게임의 유닛 이동
물류로봇의 물건 옮기기
횟집에서 음식 옮기는 로봇...
대부분 A* Path Planning 을 사용한다...
포인트는 2가지가 있다.
1. Explore
일반적으로 Map을 알고 있지만, 실제로 "가 보는 것"과는 다르다.
내 현재 위치에서 다른 인접한 위치로 "가 보는 것" 이 Search이다.
모든 Map을 다 가볼 것인지, 일부만 가볼 것인지가 핵심이다.
간다는 것 자체가 그다음 경로도 확인해 보는 것이고, 소모값이 있는 행동이기 때문이다.
2. Path
모든 길을 Explore 했지만 다양하게 펼쳐진 목적지까지의 Path 중
어떤 길이 가장 효율적인가(적은 비용이 드는가)에 대한 질문이다.
따라서 위 두가지를 모두 최적화를 시키는 것이 목적이고
그 과정에 따라
BFS - Dijkstra - Heuristic(Greedy) - A* 까지 발전하게 된다.
Dijkstra = BFS + Path 최적화
Heuristic = BFS + Explore 최적화
A* = BFS + Path 최적화 + Explore 최적화
이를 각각 순서대로 비교해보자
II. Breadth First Search (BFS)
1. Explore
BFS는 어떤 우선순위도 없고 방사선 모양으로 탐색한다 ( 결국 다 가본다 )

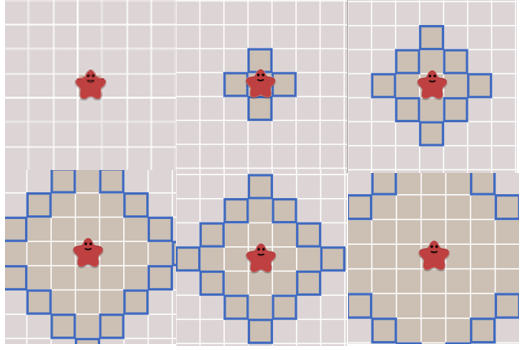
2. Path
방사선형태로 모든 Map을 탐색하기 때문에 목적지까지의 도달할 수 있는 모든 경로를 다 갖게 된다.
그렇다면 목적지 도착 했을 때는 어떤 경로로 왔는지 어떻게 확인할까??
- 돌아온 길을 List, 파이썬이라면 Dictionary로 기록해 두어 목표 도착 시 역으로 추적한다.
3. Code
이해를 쉽게 하기 위해 간소화
int BFS(){
while(!Q.empty()){
Position curP = Q.pop();
// 인접 경로 확인(next에 대입)
for(int neighborIdx=0; neighborIdx<getNeighborLen(curP);neighborIdx++){
Position nextP = getNeighbor(curP, neighborIdx);
//방문 안했다면 Q에 넣음
if(notAlreadyVisit(nextP)) {
nextP.camefrom = curP; // 돌아온 곳 기록
Q.push(nextP);
}}// Q를 모두 탐색하며 전체 경로 탐색한다.
III. Dijkstra (다익스트라)
" Dijkstra는 BFS에서 "Cost" 개념을 이용해 Path만 최적화시킨 개념이다.
Map의 각 요소에 비용(Cost)이 붙으며 그 비용에 따라 움직인다.
1. Explore
BFS에서 "Path"를 향상한 방식이다. 즉, 결국 모든 Map을 다 탐색한다.
다만, BFS와 다른 점은 탐색 우선순위가 있다는 것인데,
이 계산을 위해 비용(Cost)을 사용한다.


초록색 Map (High Cost)는 탐색이 더디게 되고 있다.
명심할 점은
"우선순위가 있다 = 결국 모든 곳을 탐색하게 된다"이다.
우리는 이 탐색 순서만 바꿔줄 뿐이다.
2. Path
하지만 Cost를 어떻게 사용하여 더디게 탐색하고, 길을 만들까?
원리는 다음과 같다.
Cost 사용원리
탐색을 한다 = 코드 구현상 Queue에 넣는 것이다.
이때 모든 Map에는 그 위치의 Cost가 있어서
Path Planning을 위한 Cost는 다음과 같이 계산한다.
Cost = (Next 위치의 Cost) + (Start~Cur 위치까지의 누적 Cost)
이 Cost를 함께 계산하여 탐색을 위한 Queue에 넣는다.
그리고 Cost가 낮은 장소부터 우선 탐색한다. = Priority Queue 사용
그렇게 된다면 최종 목적지에서 역으로 탐색할 때
도달 가능한 모든 경로(BFS)에서
가장 낮거나 같은 Cost를 가진 경로로 최적화가 된다.(Dijkstra)
3. Code
int Dijkstra(){
while(!priorityQ.empty()){
Position curP = Q.pop();
// 인접 경로 확인(next에 대입)
for(int neighborIdx=0; neighborIdx<getNeighborLen(curP);neighborIdx++){
Position nextP = getNeighbor(curP, neighborIdx);
//핵심 cost 코드
int newPathCost = curP.cost + getMapCost(nextP);
// 첫 방문이거나 이미 저장된 Cost가 현재 경로보다 높으면 갈아치움
if(notAlreadyVisit(nextP) || newCost < getTotalCost(nextP)) {
nextP.pathCost = newPathCost; // 경로찾기를 위한 Path Cost 저장
nextP.ExplorePriority = nextP.pathCost // Q를 위한 Path Cost 저장
nextP.camefrom = curP; // 돌아온 곳 기록
priorityQ.push(nextP);
}}
Priority Queue는 쉽게
원하는 조건대로 정렬시켜 push 하는 것으로 구현 가능하다.
이 경우 ExplorePriority 오름차순으로 정렬하게 될 것이다.
ExplorePriority는 Dijkstra에서 pathCost가 된다.
결론 : BFS에서 추가된 점은 Cost 계산과 Queue에서 다음 탐색할 위치를 결정하는 것뿐이다.
BFS : Push 한 순서대로 그저 Pop 하여 탐색
Dijkstra : Push한 순서 상관없이 낮은 Cost에 따라 Pop 하여 탐색
IV. Heuristic (Greedy Search)
휴리스틱이라고 불리는 이 탐색 기법은 Greedy 기법으로 Greedy BFS라고도 불린다.
탐색 기법인 만큼 BFS + Explore 최적화라고 볼 수 있다.
1. Explore
Greedy란 알고리즘 문제풀이로도 자주 나오는, 탐욕 기법으로
이것저것 따지지 말고 목표에 가장 근접한 Step만 쫓아 가는 것이다.
(여기로 돌아가면 더 빠르지 않을까 이런 생각 안 함)
Path Planning에서 Greedy 하게 끔 만들어 주는 것을 Heuristic 함수라고 하며
이 Heuristic 함수(이하 H)는 주로 목적지까지의 거리 혹은 시간으로 정의된다.
H와 Explore가 합쳐지면 가장 Greedy 한 방향으로만 탐색하게 된다.
예를 들어 목적지 반대는 H = distance 값이 커지게 되므로 아예 탐색 관심도 없는 것.
따라서 전체를 다 탐색해야 하는 BFS와 달리 탐색조차도 거르기 때문에
프로그램 성능이 매우 향상된다.


2. Path
BFS랑 다를 것 없이 방문을 기록하여 목적지 도달 시 역으로 추적한다.
하지만 BFS도 그랬듯 Path에 문제점이 있다. Explore만 최적화하고 온 길을 그저 기록하니
최적의 Path를 모른다!!

만약 Dijkstra였다면, 탐색은 전체를 하겠지만,
Path Cost를 기록하니 최적 위치는 아래와 같이 찾을 수 있다.

3. Code
int GreedySearch(){
while(!priorityQ.empty()){
Position curP = Q.pop();
// 인접 경로 확인(next에 대입)
for(int neighborIdx=0; neighborIdx<getNeighborLen(curP);neighborIdx++){
Position nextP = getNeighbor(curP, neighborIdx);
// 첫 방문이거나 이미 저장된 Cost가 현재 경로보다 높으면 갈아치움
if(notAlreadyVisit(nextP)) {
//핵심 Heuristic 코드
int Heuristic = getDistance(nextP, goalP)
nextP.ExplorePriority = Heuristic; // ExplorePriority 저장
nextP.camefrom = curP; // 돌아온 곳 기록
priorityQ.push(nextP);
}}
Priority Queue는 쉽게
원하는 조건대로 정렬시켜 push 하는 것으로 구현 가능하다.
이 경우 ExplorePriority (H) 를 오름차순으로 정렬하게 될 것이다.
핵심은 현재 위치에서 인접한 다음 위치의 Heuristic을 저장하는 것이다.
사실상 Dijkstra처럼 모든 위치가 Queue에 저장되지만
Greedy 기법이므로(거리(H)가 역전될 수 없으므로) 절대 모두 탐색할 수 없다.
V. A* (A star)
A*를 공부하다가 여기까지 오게 되었다.
결론적으로 BFS + Dijkstra + Heuristic이다.
BFS는 Explore, Path 모두 비 효율적이었고
Dijkstra는 최적 Path는 알지만 Explore가 비 효율적이었다.
Heuristic은 Explore는 최적화되어있지만 Path는 비 효율적이었다.
따라서 Path의 Cost계산과 Explore의 Cost계산을 합치면 A*가 된다.
Dijkstra에서 Cost = CurPosition까지 누적 + NextPosition의 자체 Cost
Heuristic의 Cost = H = Distance(NextPosition, Goal)
인데 A*는 둘 다 합친 것이니
A* 에서의 Cost = (CurPosition까지 누적) + (NextPosition의 자체 Cost) + (H)
가 된다.
발전 과정을 따라오니까 A*가 매우 쉬워진다.
1. Explore
Greedy의 Explore 방식을 따른다. 다음 위치 기준의 Heuristic 함수를 사용하여 탐색한다.
2. Path
Dijkstra의 Path planning 방식을 따른다.
- 현재 위치까지의 누적 Cost + 다음 Map으로 갈 때 필요한 Cost의 합으로 계산한다.
- 누적 Cost가 가장 낮은 경로를 기록하여 Path를 찾는다.

3. Code
int A_Star(){
while(!priorityQ.empty()){
Position curP = Q.pop();
// 인접 경로 확인(next에 대입)
for(int neighborIdx=0; neighborIdx<getNeighborLen(curP);neighborIdx++){
Position nextP = getNeighbor(curP, neighborIdx);
//핵심 cost 코드
int newPathCost = curP.totalCost + getMapCost(nextP);
// 첫 방문이거나 이미 저장된 Cost가 현재 경로보다 높으면 갈아치움
if(notAlreadyVisit(nextP) || newCost < getTotalCost(nextP)) {
nextP.pathCost = newPathCost; // Path Cost 저장
// 여기서 Dijkstra + Heuristic
int Heuristic = getHeuristic(nextP, goalP);
nextP.ExplorePriority = newPathCost + H; // Explore Priority 저장
nextP.camefrom = curP; // 돌아온 곳 기록
priorityQ.push(nextP);
}}
Priority Queue는 쉽게
원하는 조건대로 정렬시켜 push 하는 것으로 구현 가능하다.
이 경우 ExplorePriority를 오름차순으로 정렬하게 될 것이다.
'Algorithm > Path Planning' 카테고리의 다른 글
| [Algorithm][Path Planning] A* 구현하기 (0) | 2023.02.26 |
|---|