
ㄷ이 글은 윤성우의 TCP/IP 소켓 프로그래밍 책을 참고하였습니다.
순서
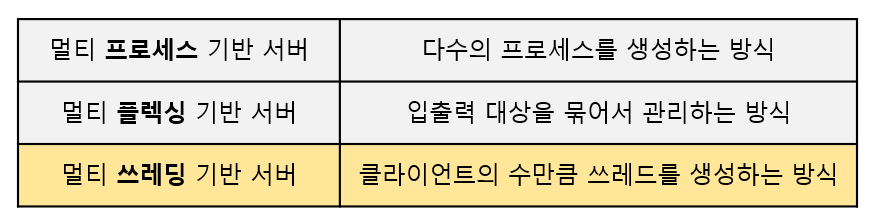
I. 스레드의 등장배경
II. 스레드의 구조
I. 스레드의 등장배경
멀티 프로세스가 장점도 있지만 큰 단점이 존재한다.
우선, 프로세스의 생성이라는(전체 복사) 작업이 운영체제 입장에서 굉장히 부담되고
각각이 독립적인 메모리 공간을 차지하기 때문에 프로세스 사이에서 메시지를 주고받기도 힘들다(IPC기법).
하지만, 다음 단점이 가장 치명적으로 작용한다
"컨텍스트 스위칭(Context Switching)"에 의한 부담이다.
컨텍스트 스위칭이란?
프로그램의 실행을 위해서는 해당 프로세스의 정보가 메인 메모리에 올라와야한다.
예를들면 현재의 A 프로세스 관련 데이터를 내리고, B프로세스를 메인 메모리로 이동시키는 것이다.
이렇게 데이터를 이동시키는 과정이 바로 컨텍스트 스위칭이다.
이때, 내려온 A프로세스 관련 데이터는 하드디스크로 이동하기 때문에 시간이 길어지고 한계가 있다.
결국 스레드는 멀티프로세스의 특징을 유지하면서 이러한 단점들을 극복하기(최소화) 위해서 등장했다.
일종의 경량화 된 프로세스라고 보면 된다. 이런 스레드는 프로세스 대비 다음과 같은 장점이 있다.
1. 스레드의 생성 및 컨텍스트 스위칭은 프로세스의 그것들 보다 빠르다.
2. 스레드 사이에서의 데이터 교환에는 특별한 기법이 필요치 않다.
II. 스레드의 구조
스레드의 구조를 보기 전에 먼저 프로세스의 메모리 구조를 보자.
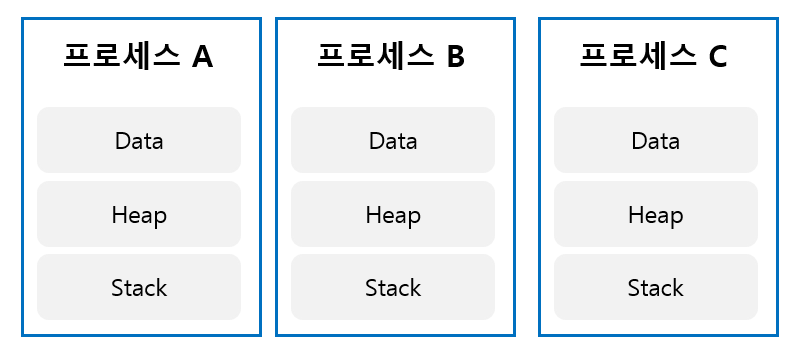
데이터 영역(Data) : 전역변수 할당
힙 영역 (Heap) : malloc, new 등 동적 할당
스택 영역(Stack) : 함수의 실행에 사용
둘 이상의 실행흐름을 갖게 하는것이 목적이라면, 굳이 Data와 Heap까지 따로 분리해야할까?
그래서~ Stack만 분리시킨것이 스레드이고, 이로써 위의 두 가지 장점을 설명할 수 있다.
1. 컨텍스트 스위칭 시 데이터 영역과 힙은 올리고 내릴 필요가 없다.
2. 데이터 영역과 힙을 이용해서 데이터를 교환할 수 있다.
다음은 스레드의 메모리 구조이다.
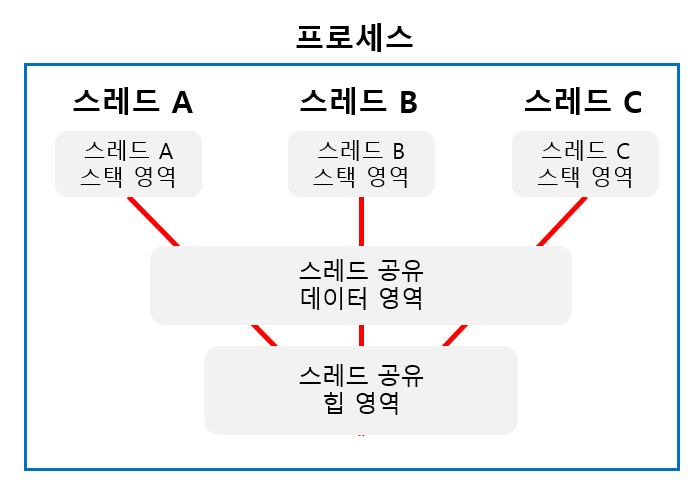
위의 그림2와 같이 스레드는 프로세스 내에서 생성 및 실행되는 구조로 이루어져있다.
즉, 프로세스와 스레드는 다음과 같이 정의할 수 있을것이다.
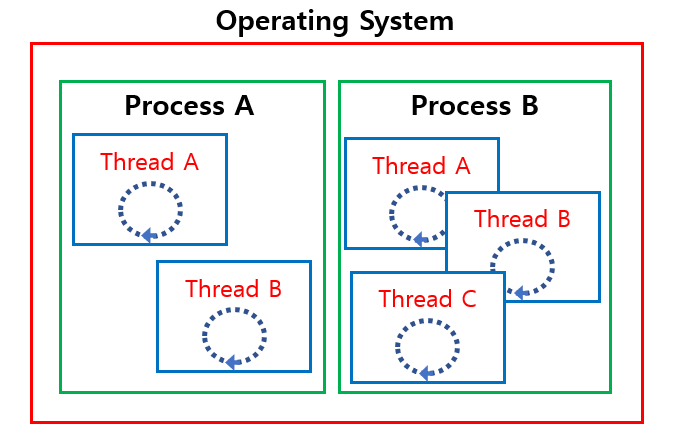
프로세스 : 운영체제 관점에서 별도의 실행흐름을 구성하는 단위
스레드 : 프로세스 관점에서 별도의 실행흐름을 구성하는 단위
최종적으로 운영체제-프로세스-스레드의 구조를 보자.
'Programming > Network(C++)' 카테고리의 다른 글
| [Network][Thread] 멀티스레드(3)_동시접근의 문제점 (0) | 2020.12.21 |
|---|---|
| [Network][Thread] 멀티스레드(2)_스레드의 생성 및 실행(pthread)(Linux) (0) | 2020.12.20 |
| [Network][TCP/IP] 멀티 플렉싱(5)_레벨, 엣지 트리거(Only Linux) (0) | 2020.12.19 |
| [Network][TCP/IP] 멀티 플렉싱(4)_epoll 함수로 구현(Only Linux) (0) | 2020.12.19 |